Syllable segmentation in Cornish - forward vs. backward segmentation
Tags: kernewekPythonnatural language processingcornish14 Aug 2016 - MawKernewek
The syllable segmentation module of TaklowKernewek I have commented on earlier in this blog, and on my website.
However there is much more to discuss, and one aspect of this is that the program offers a choice between forwards and backwards segmentation.
This means either starting from the beginning of the word, and working forwards assigning the letters to particular syllables, or starting from the end and working backwards.
I present some of the code from the program, which is admittedly difficult to read, and if you like, skip down to the examples at the bottom. It may also be easier to read at my Bitbucket site.
The core of this program is a set of regular expressions, as follows:
In the actual segmentation of the word itself, the expressions
where
The
A similar effect can be seen in another sentence:
However there is much more to discuss, and one aspect of this is that the program offers a choice between forwards and backwards segmentation.
This means either starting from the beginning of the word, and working forwards assigning the letters to particular syllables, or starting from the end and working backwards.
I present some of the code from the program, which is admittedly difficult to read, and if you like, skip down to the examples at the bottom. It may also be easier to read at my Bitbucket site.
The core of this program is a set of regular expressions, as follows:
# syllabelRegExp should match syllable anywhere in a word
# a syllable could have structure CV, CVC, VC, V
# will now match traditional graphs c-, qw- yn syllable initial position
syllabelRegExp = r'''(?x)
((bl|br|Bl|Br|kl|Kl|kr|Kr|kn|Kn|kwr?|Kwr?|qwr?|Qwr?|ch|Ch|Dhr?\'?|dhr?\'?|dl|dr|Dr|fl|Fl|fr|Fr|vl|Vl|vr|Vr|vv|ll|gwr?|gwl?|gl|gr|gg?h|gn|Gwr?|Gwl?|Gl|Gr|Gn|hwr?|Hwr?|ph|Ph|pr|pl|Pr|Pl|shr?|Shr?|str?|Str?|skr?|Skr?|skw?|Skw?|sbr|Sbr|spr|Spr|sp?l?|Sp?l?|sm|Sm|tth|Tth|thr?|Thr?|tr|Tr|tl|Tl|wr|Wr|wl|Wl|[bckdfjvlghmnprstwyzBCKDFJVLGHMNPRSTVWZY]) # consonant
\'?(ay|a\'?w|eu|ey|ew|iw|oe|oy|ow|ou|uw|yw|[aeoiuy])\'? #vowel
(lgh|ls|lt|bl|br|bb|kl|kr|kn|kwr?|kk|n?ch|dhr?|dl|n?dr|dd|fl|fr|ff|vl|vv|gg?ht?|gw|gl|gn|ld|lf|lk|ll|mm|mp|nk|nd|nj|ns|nth?|nn|ph|pr|pl|pp|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rr|rj|rf|rs|sh|st|sk|ss|sp?l?|tt?h|tt|[bdfgljmnpkrstvw])? # optional const.
)| # or
(\'?(ay|a\'?w|eu|ew|ey|iw|oe|oy|ow|ou|uw|yw|Ay|Aw|Ey|Eu|Ew|Iw|Oe|Oy|Ow|Ou|Uw|Yw|[aeoiuyAEIOUY])\'? # vowel
(lgh|ls|lt|bl|bb|kl|kr|kn|kwr?|kk|cch|n?ch|dhr?|dl|n?dr|dd|fl|fr|ff|vl|vv|gg?ht?|gw|gl|gn|ld|lf|lk|ll|mm|mp|nk|nd|nj|ns|nth?|nn|ph|pr|pl|pp|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rr|rj|rf|rs|sh|st|sk|ss|sp?l?|tt?h|tt|[bdfgljmnpkrstvw]\'?)?) # consonant (optional)
'''
# diwethRegExp matches a syllable at the end of the word
diwetRegExp = r'''(?x)
((bl|br|Bl|Br|kl|Kl|kr|Kr|kn|Kn|kwr?|Kwr?|qwr?|Qwr?|ch|Ch|Dhr?\'?|dhr?\'?|dl|dr|Dl|Dr|fl|Fl|fr|Fr|vl|Vl|vr|Vr|vv|ll|gwr?|gwl?|gl|gr|gg?h|gn|Gwr?|Gwl?|Gl|Gr|Gn|hwr?|Hwr?|ph|Ph|pr|pl|Pr|Pl|shr?|Shr?|str?|Str?|skr?|Skr?|skw?|Skw?|sbr|Sbr|spr|Spr|sp?l?|Sp?l?|sm|Sm|tth|Tth|thr?|Thr?|tr|Tr|tl|Tl|wr|Wr|wl|Wl|[bckdfjlghpmnrstvwyzBCKDFJLGHPMNRSTVWYZ]\'?)? #consonant or c. cluster
\'?(ay|a\'?w|eu|ew|ey|iw|oe|oy|ow|ou|uw|yw|Ay|Aw|Ey|Eu|Ew|Iw|Oe|Oy|Ow|Ou|Uw|Yw|\'?[aeoiuyAEIOUY]\'?) # vowel
(lgh|ls|lt|bl|br|bb|kl|kr|kn|kwr?|kk|cch|n?ch|dhr?|dl|n?dr|dd|fl|fr|ff|vl|vv|gg?ht?|gw|gl|gn|ld|lf|lk|ll|mm|mp|nk|nd|nj|ns|nth?|nn|ph|pr|pl|pp|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rr|rj|rf|rs|sh|st|sk|ss|sp?l?|tt?h|tt|[bdfgjklmnprstvw]\'?)? # optionally a second consonant or cluster ie CVC?
(\-|\.|\,|;|:|!|\?|\(|\))*
)$
'''
# kynsaRegExp matches syllable at beginning of a word
# 1st syllable could be CV, CVC, VC, V
kynsaRegExp = r'''(?x)
^((\'?(bl|br|Bl|Br|kl|Kl|kr|Kr|kn|Kn|kwr?|Kwr?|qwr?|Qwr?|ch|Ch|Dhr?|dhr?|dl|dr|Dr|fl|Fl|fr|Fr|vl|Vl|vr|Vr|gwr?|gwl?|gl|gr|gn|Gwr?|Gwl?|Gl|Gr|Gn|hwr?|Hwr?|ph|Ph|pr|pl|Pr|Pl|shr?|Shr?|str?|Str?|skr?|Skr?|skw?|Skw?|sbr|Sbr|spr|Spr|sp?l?|Sp?l?|sm|Sm|tth|Tth|thr?|Thr?|tr|Tr|tl|Tl|wr|Wr|wl|Wl|[bckdfghjlmnprtvwyzBCKDFGHJLMNPRTVWYZ])\'?)? # optional C.
\'?(ay|a\'?w|eu|ew|ey|iw|oe|oy|ow|ou|uw|yw|Ay|Aw|Ey|Eu|Ew|Iw|Oe|Oy|Ow|Ou|Uw|Yw|[aeoiuyAEIOUY])\'? # Vowel
(lgh|ls|lk|ld|lf|lt|bb?|kk?|cch|n?ch|n?dr|dh|dd?|ff?|vv?|ght|gg?h?|ll?|mp|mm?|nk|nd|nj|ns|nth?|nn?|pp?|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rj|rf|rs|rr?|sh|st|sk|sp|ss?|tt?h|tt?|[jw]\'?)? # optional C.
(\-|\.|\,|;|:|!|\?|\(|\))*
)'''
In the actual segmentation of the word itself, the expressions
kynsaRegExp and diwetRegExp are used, depending on whether we are going forwards starting from the beginning or backwards from the end:
if fwds:
# go forwards
sls = rannans.ranna_syl(self.graph,regexps.kynsaRegExp,fwd=True,bwd=False)
else:
# go backwards from end
sls = rannans.ranna_syl(self.graph,regexps.diwetRegExp,fwd=False,bwd=True)
where
ranna_syl() is the actual function that returns a list of syllables from the word ger:
def ranna_syl(self,ger,regexp,fwd=True,bwd=False):
""" divide a word into a list of its syllables
and return this as a list of plain text strings
"""
syl_list = []
if fwd:
# go forwards through the word
while ger:
# print(ger)
k = self.match_syl(ger,regexp)
# print("kynsa syl:{k}".format(k=k))
# add the syllable to the list
if k != '':
syl_list.append(k)
if k != '' and len(ger.split(k,1))>1:
# if there is more of the word after the
# 1st syllable
# remove the 1st syllable
ger = ger.split(k,1)[1]
else:
ger = ''
if bwd:
# go backwards from the end through the word
while ger:
# print(ger)
d = self.match_syl(ger,regexp)
# print(d)
# add the syllable to the list
if d != '':
syl_list.insert(0,d)
if d != '' and len(ger.rsplit(d,1))>1:
# if there is more of the word before the
# last syllable
# remove the last syllable
ger = ger.rsplit(d,1)[0]
else:
ger = ''
# this is returning
# a list of plain text
# not Syllabenn objects
return syl_list
The
syllabelRegExp regular expression is used in Syllabenn class itself, as part of the code that initates a Syllabenn object and works out the syllable parts, i.e. consanant clusters and vowels, and the overall length.Example sentences
The effect of going forwards or backwards can be illustrated in the processing of an example sentence: |
| Going backwards from the end, tends to maximise consonants at the beginning of syllables. For example the word 'gewer' is processed into ['ge', 'wer'] i.e. the w is assigned to the second syllable whereas in this word the 'ew' is actually pronounced as a diphthong. The gemminated consonant 'mm' in lemmyn is split into two different syllables. |
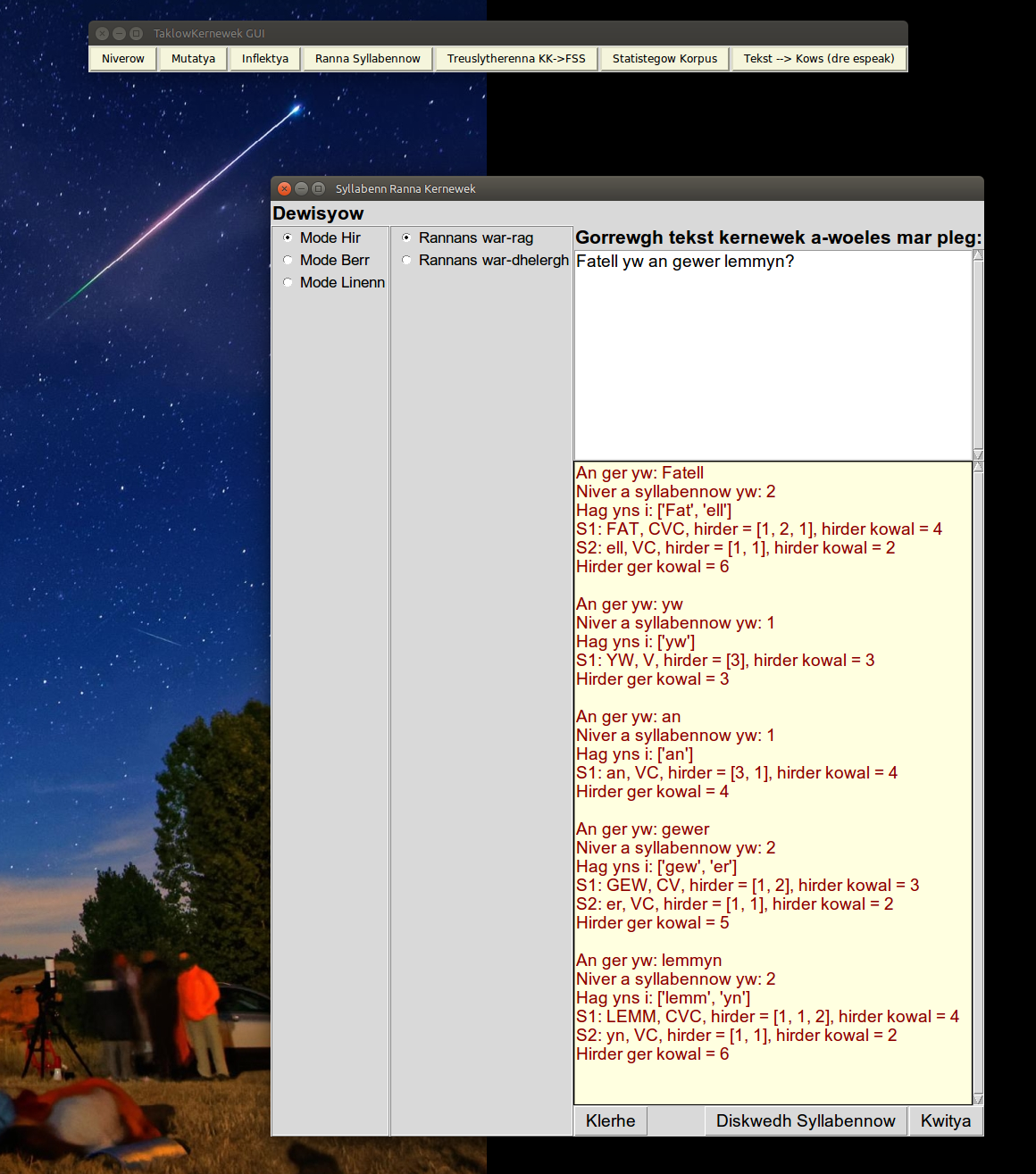 | |
| Now working forward, the processing of the word 'gewer' now splits into ['gew', 'er'] which accords with the status of 'ew' as a diphthong. 'Lemmyn' now splits into ['lemm', 'yn'] assigning the whole of the gemminated consonant to the first syllable. The word 'Fatell' now has the 't' assigned to the first syllable |
A similar effect can be seen in another sentence:
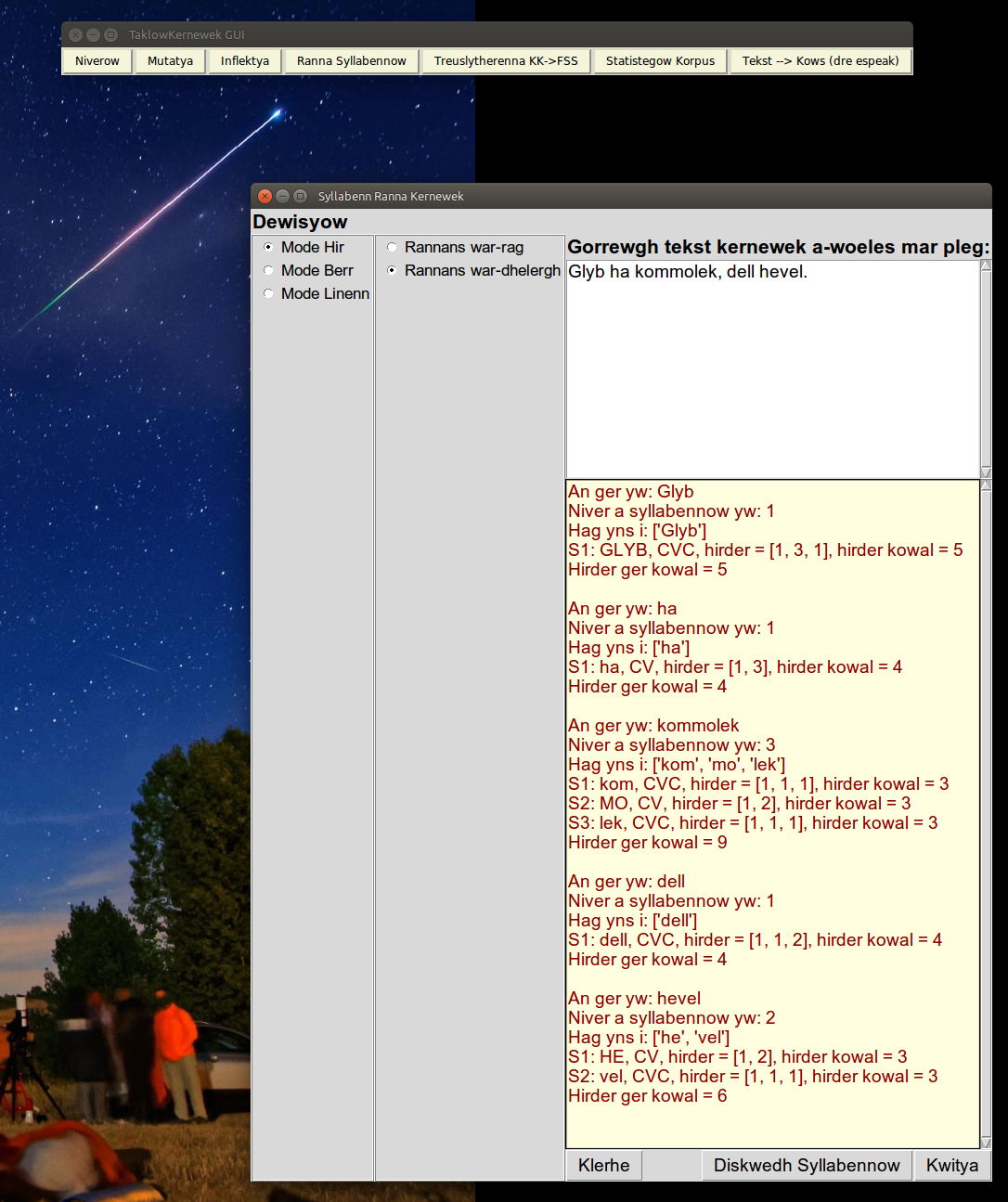 |
| Special cases such as the unstressed monosyllables 'ha', and 'dell' are detailed in the file datageryow.py. |
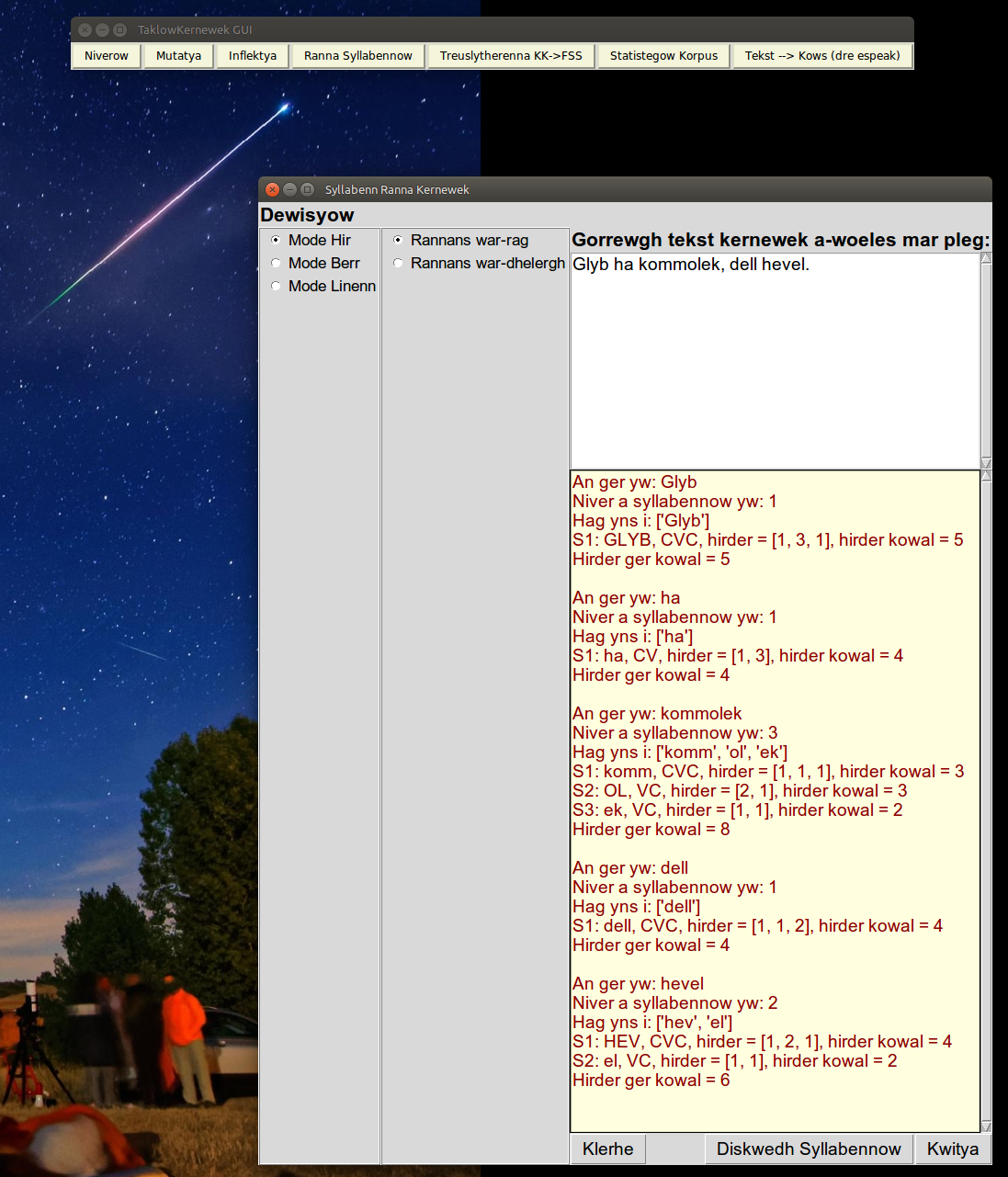 |
| With forwards segmentation, the processing of 'kommolek', and 'hevel' assigns consonants to the coda of syllables rather than maximising the onset. |