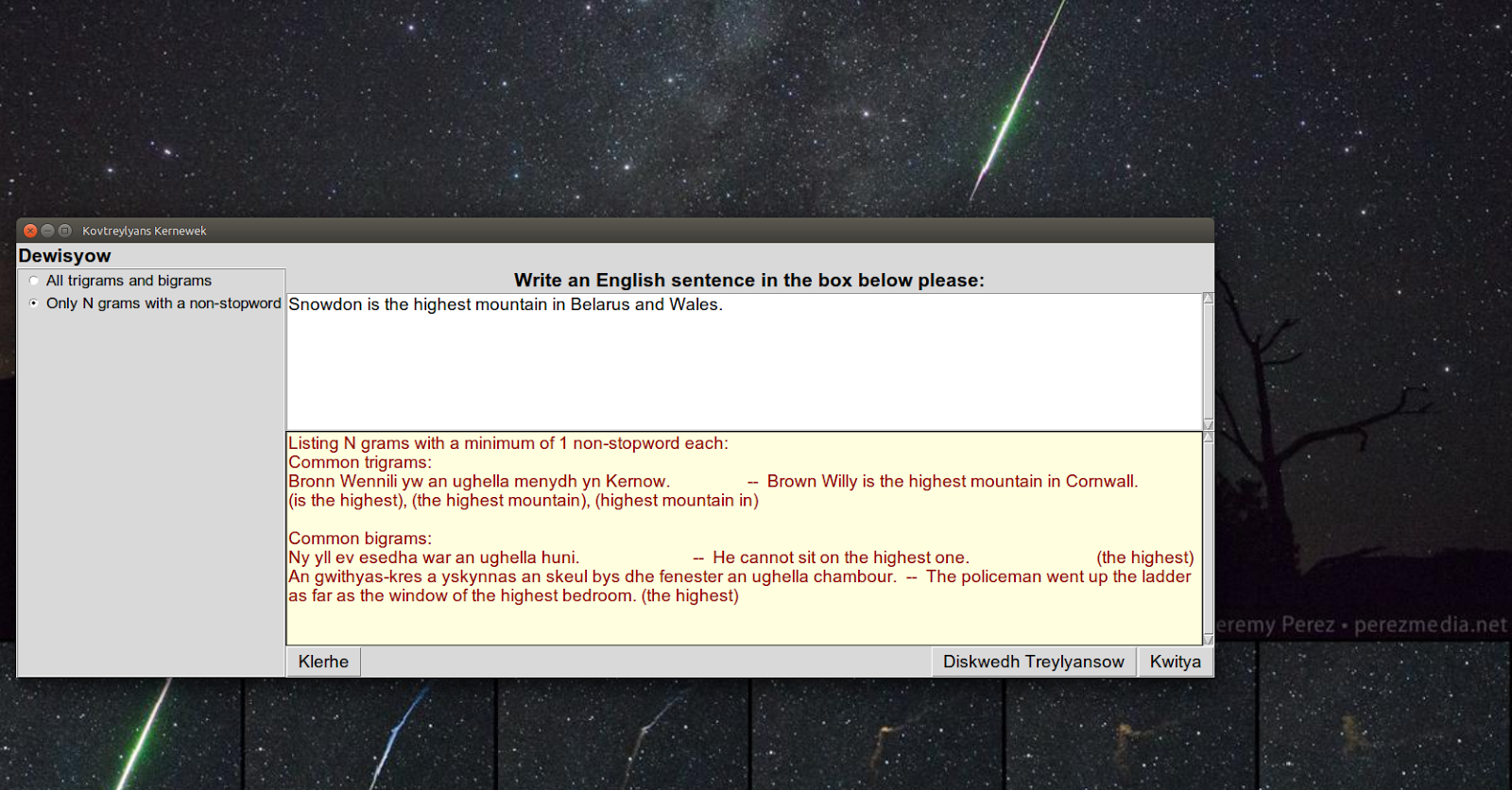
I have developed the translation memory software a little further as part of my
TaklowKernewek tools.
It now has a GUI:
 |
| Using only bigrams and trigrams from the corpus that contain at least one non stopword (based on NLTK stopwords corpus). |
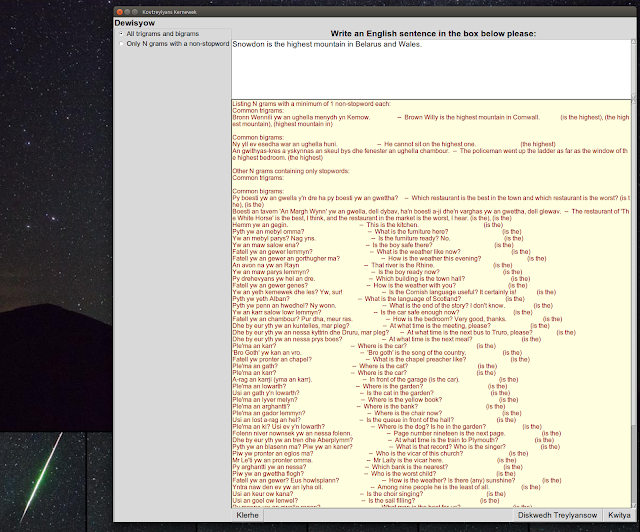 |
| Showing all bigrams and trigrams outputs a long list of sentences containing ('is', 'the'). |
 |
| Sentences in the corpus that contain multiple trigrams in common with the input are ranked highest, and similarly with bigrams. |
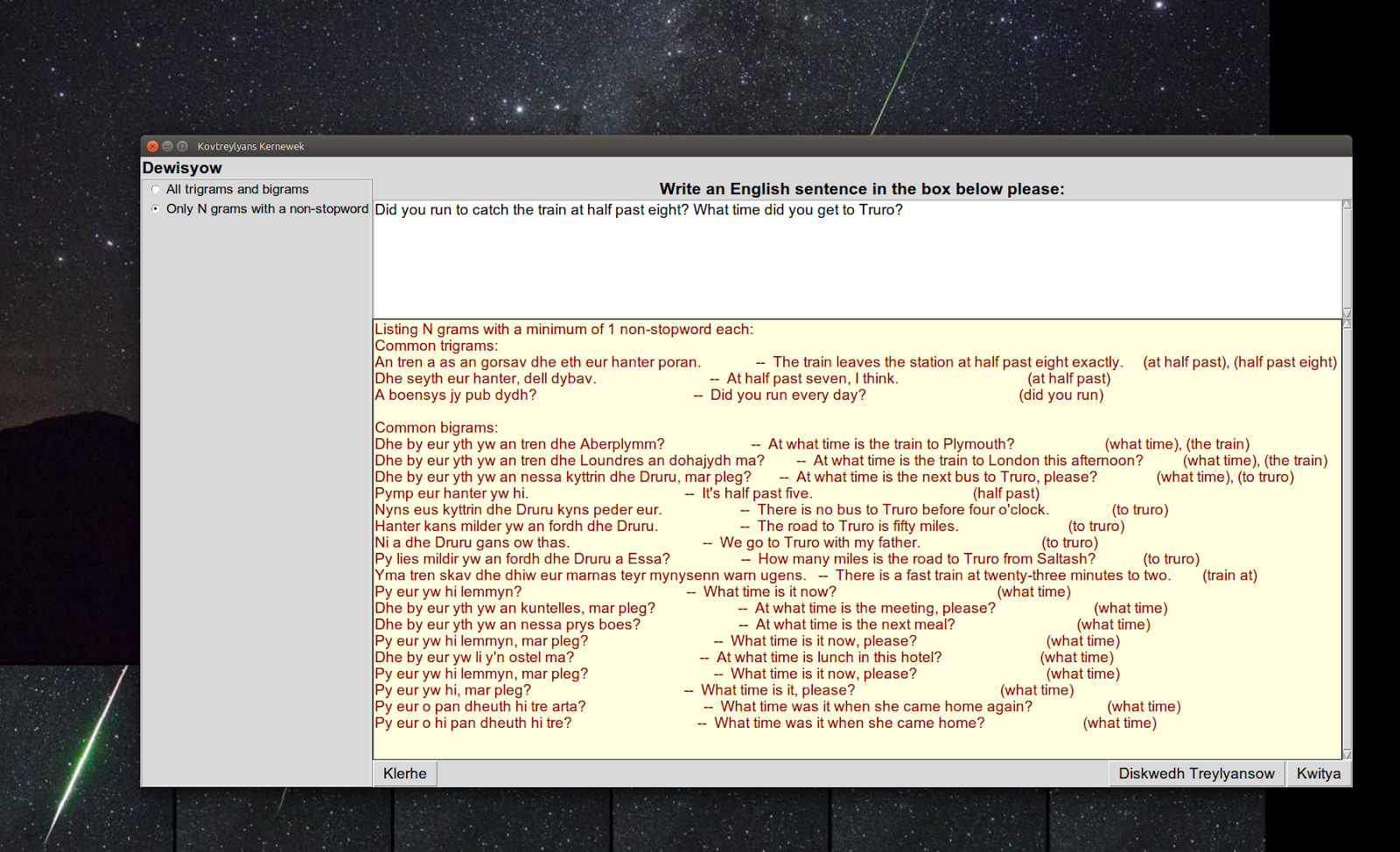
After improvement to the text wrapping of the output sentences to split longer lines: