Skrifennow
My blog, imported from Blogger and converted using Jekyll.
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
Next »
Tomatoes and chillis in mini-greenhouse outside
The weather was getting warmer this time last week so I put my mini greenhouse outdoors and the tomato plants into it, along with some of my chilli seedlings. Thus far they have done OK, although it looks like frost again tonight with possibility of snow.


 |
| The primrose plant flowering in a hanging basket containing some strawberry plants as well |
 |
| Daffodils on the left, with a blueberry plant along with some strawberry plants that I grew from runners last year. The spruce in the pot isn't looking too healthy, with most of the needles turned brown. |
 |
| Some new growth is evident on the transplanted strawberry plants. |
 |
| Dwarf daffodils, and some crocuses that have been beaten down by recent rain. Some sweet pea plants that I grew from an autumn sowing have recently been planted, although I have kept the better seedlings in my parents greenhouse to wait until the daffodils finish before transplanting them. |


 |
| The mini greenhouse, showing tomato plants and chilli seedlings. |
 |
| A temperature sensor is located in between the two trays, one of which contains chilli seedlings from my own plants from last year, and the other seeds ordered from Greece. |
 |
| the two plants on the right are Chilean guava (Ugni molinae). |
 |
| The temperature sensor display, showing the external sensor with a temperature of 4.5°C at this time. I have put a tandorri pot, filled with hot water from the kettle, in an effort to keep the greenhouse temperature above freezing. I first did this around 9pm but didn't add any insulation to the greenhouse, and then did so again from 12:30am the original water being cool by then, and added a flanel shirt and fleece jacket to the greenhouse. |
 |
| a fleece covering the top of the greenhouse |
 |
| The tandoori pot filled with hot water |
 |
| The temperature was at just over 2°C before the hot water was put in, and rose to 4°C a few minutes after the picture was taken. |
Skinners Brewery Tour in Kernewek
The Prag Na project (blog, facebook) has been organising social events using the Cornish language, and one of these was a tour of Skinners Brewery Truro on 16th March.
We had an excellent tour thanks to Emma from Skinners Brewery and Pol Hodge translating into Kernewek. Of course we also sampled the very good ales, and had a pasty. Once a few pints of ale were down we sang a few songs in Kernewek and much merriment was had by all.
We even had a story by Loveday and Pol about saints Piran and Patrick (recording by Rob Lawrance)
Here are some pictures of the event:








We had an excellent tour thanks to Emma from Skinners Brewery and Pol Hodge translating into Kernewek. Of course we also sampled the very good ales, and had a pasty. Once a few pints of ale were down we sang a few songs in Kernewek and much merriment was had by all.
We even had a story by Loveday and Pol about saints Piran and Patrick (recording by Rob Lawrance)
Here are some pictures of the event:
 |
| Emma from Skinners along with Pol Hodge translating into Cornish |





 |
| Boxes of hops. These are not grown in Cornwall as the climate isn't very suitable but can be from a number of sources including Kent, Worcestershire, USA, Czech Republic and Slovenia. |

 |
| In the vessel pictured, steam is added to the barley to produce a liquid known as 'wort'. |
 |
| The copper on the right was formerly used in a Scotch whisky distillery |


Spring bulbs coming out
In the containers I have outside my flat, I have some spring bulbs planted, which are now coming out (photos taken today, 17th February).
There are crocuses, dwarf irises (not yet) and dwarf daffodils.
Meanwhile, the gooseberrys, blueberries, tayberry and blackberry are still in winter dormancy though some leaf buds are evident.
The strawberries are variable in their success, but time will tell as spring progresses whether they come back well this year.
Some plants appear to have died (such as the Coleus in the ground container which was attacked immediately by slugs after its planting and now is only a stick of a stem).
There are crocuses, dwarf irises (not yet) and dwarf daffodils.
Meanwhile, the gooseberrys, blueberries, tayberry and blackberry are still in winter dormancy though some leaf buds are evident.
The strawberries are variable in their success, but time will tell as spring progresses whether they come back well this year.
Some plants appear to have died (such as the Coleus in the ground container which was attacked immediately by slugs after its planting and now is only a stick of a stem).
 |
| The crocuses in a tub with purple pansies which have now finished flowering. The remains of the coleus plants that had striking green and red foliage, which was also tasty to the local slug population are also visible. Some pots with daffodils are behind them, along with one of the blueberry plants. |
 |
| A fushia showing some new leaf growth, along with crocuses, geraniums and a strawberry plant. The Callibrachoa on the left looks like it is dead. |
 |
| Another one of the trough containers with daffodils and crocuses in flower, and the second blueberry plant. |
 |
| The yellow pansies (now finished flowering) along with some more spring bulbs. |
 |
| The tayberry and blackberry plants are tied to the trellis, awaiting the spring to return so they can come to life. They were planted last year and only produced a handful of berries but did grow these canes that should hopefully produce more this year. |
 |
| More of the crocuses in flower. |
 |
| This strawberry plant looks fairly healthy, and the primrose is also flowering. |
 |
| The two plants in the large pots at lower-left are Chilean Guavas (Ugni Molinea). The hanging basket above contains alpine strawberry, parsley and mint. |
Temperature monitoring of heated propagator tray
I was curious about what the temperature in my heated propagator trays where my chilli and pepper seedlings are.
I am using a Garland 7 windowsill propagator, which is heated but not thermostatically controlled.
This was on a cold winter's day with the temperature only a few degrees above freezing outside, but next to a south facing window, with the window closed. The room heating is only on for an hour in the morning before the recording started, and a few hours in the evening, and radiator is on the other side of the room from this window.
I used a Temper1 USB temperature probe.
It may be better to place the probe further from the side of the tray where direct sunlight shines on it, to get a more representative signal.
I am using a Garland 7 windowsill propagator, which is heated but not thermostatically controlled.
This was on a cold winter's day with the temperature only a few degrees above freezing outside, but next to a south facing window, with the window closed. The room heating is only on for an hour in the morning before the recording started, and a few hours in the evening, and radiator is on the other side of the room from this window.
I used a Temper1 USB temperature probe.
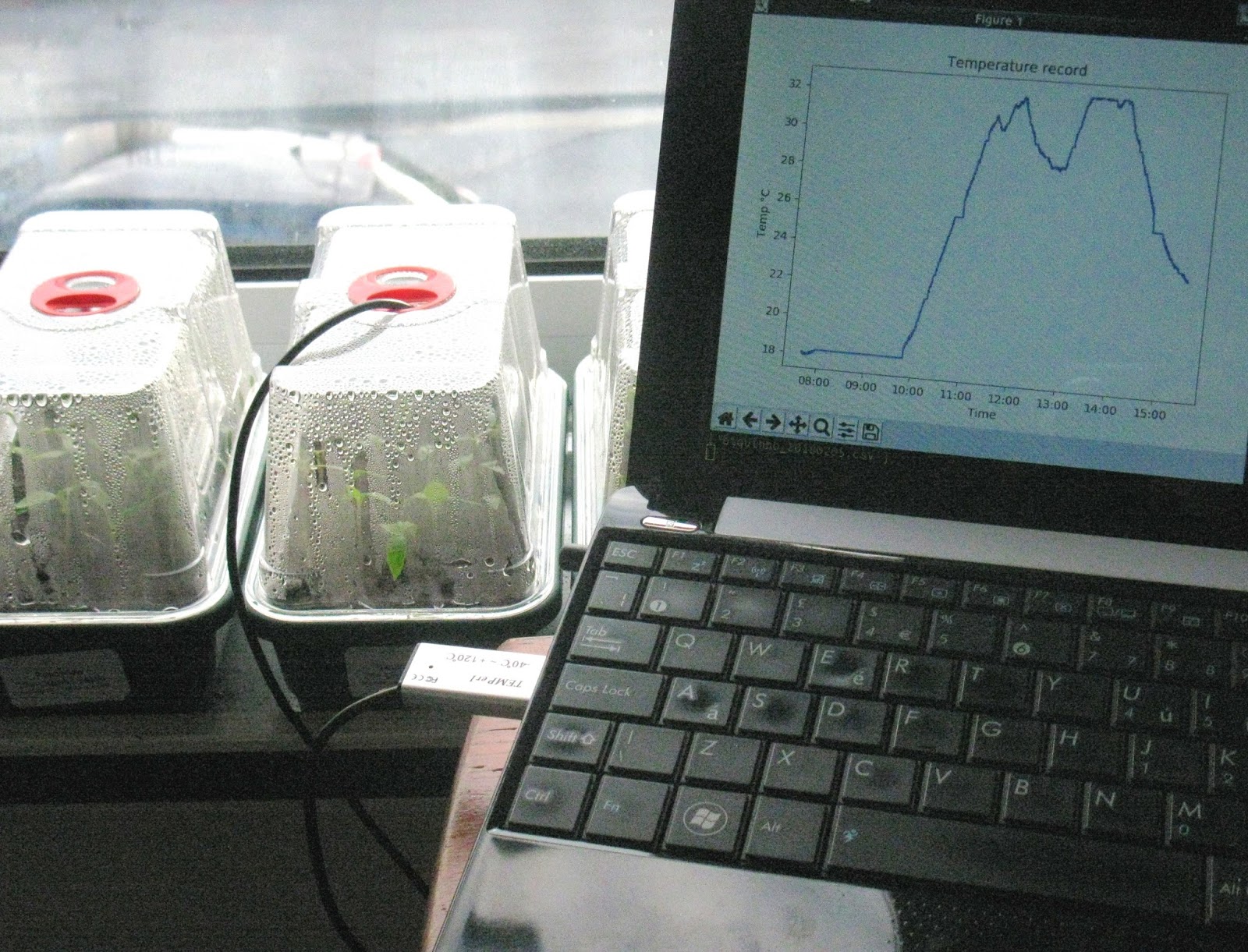 |
| The probe itself was on the side of the tray facing the window, buried in the compost. During the day, the temperature reached 32°C inside the tray, though this was at the side directly having sunlight shining on it. |
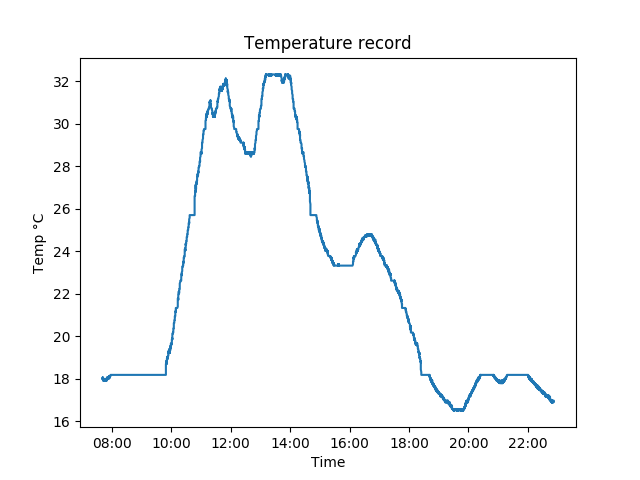 |
| The output of the temper1 sensor can be redirected to a .csv file, which I here plot using Python+matplotlib. |
Update
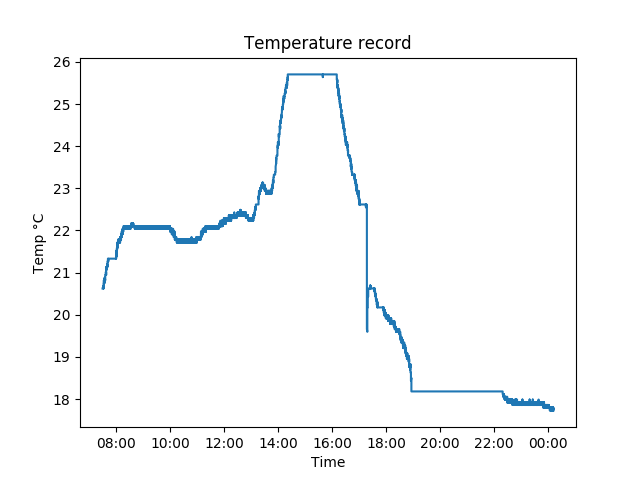 |
| The temperature on 6th February, when I placed the probe in the side of the tray, rather than the end facing the window. There was snow this morning, and not really any direct sunlight unlike the previous day. |
 |
| The first stage of potting the chilli seedlings on from the propagator trays. Most of them have been placed 2 to each cell, with some in an individual cell. |
Update on chilli and tomato seedlings
As of now, 12 out of the 15 cherry tomato seeds have germinated.
The chillis, both those that came from the seeds I saved from my plants sown in 2016 and 2017, and the mainly sweet pepper varieties I ordered from someone in Greece on eBay, are germinating well too:
Many of the plants from the previous years are still going strong including the parent plants of some of the seeds above:
It remains to be seen how many of the ones that are overwintering in my parents greenhouse will survive and grow back.
 |
| Since there are maximum three tomato seedlings in each tray, they can stay in the propagator trays for a while. |
 |
| 1602 is a habenero, not sure of exact variety |
 |
| 1701 could be Yellow Cayenne or Aji Lemon. I quite like these usually medium to hot heat but not as hot as the habeneros |
 |
| Some of the Greek sweet pepper seeds. |
 |
| 1701 is on the left, 1602 on the right. |
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
Next »