Skrifennow
My blog, imported from Blogger and converted using Jekyll.
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
Next »
Text to speech in Cornish
The program espeak offers text to speech in a variety of languages, not yet Cornish, but I have made a bit of a hack that allows Cornish text to be spoken by it.
There is a Welsh language voice for it, and I have created a script that processes Cornish text doing a series of replaces to make it conform to Welsh spelling rules.
It would be possible to get espeak to speak Cornish directly by creating a Cornish voice for it, and I did start doing this a long time ago, but unfortunately lost this work along with my previous laptop.
The GUI launcher currently only works in Linux-compatible systems, because it launches espeak via the command-line via the Python os library. However espeak itself is also available for Windows and I will adapt the script to work on Windows dreckly.
There is a Welsh language voice for it, and I have created a script that processes Cornish text doing a series of replaces to make it conform to Welsh spelling rules.
It would be possible to get espeak to speak Cornish directly by creating a Cornish voice for it, and I did start doing this a long time ago, but unfortunately lost this work along with my previous laptop.
The GUI launcher currently only works in Linux-compatible systems, because it launches espeak via the command-line via the Python os library. However espeak itself is also available for Windows and I will adapt the script to work on Windows dreckly.
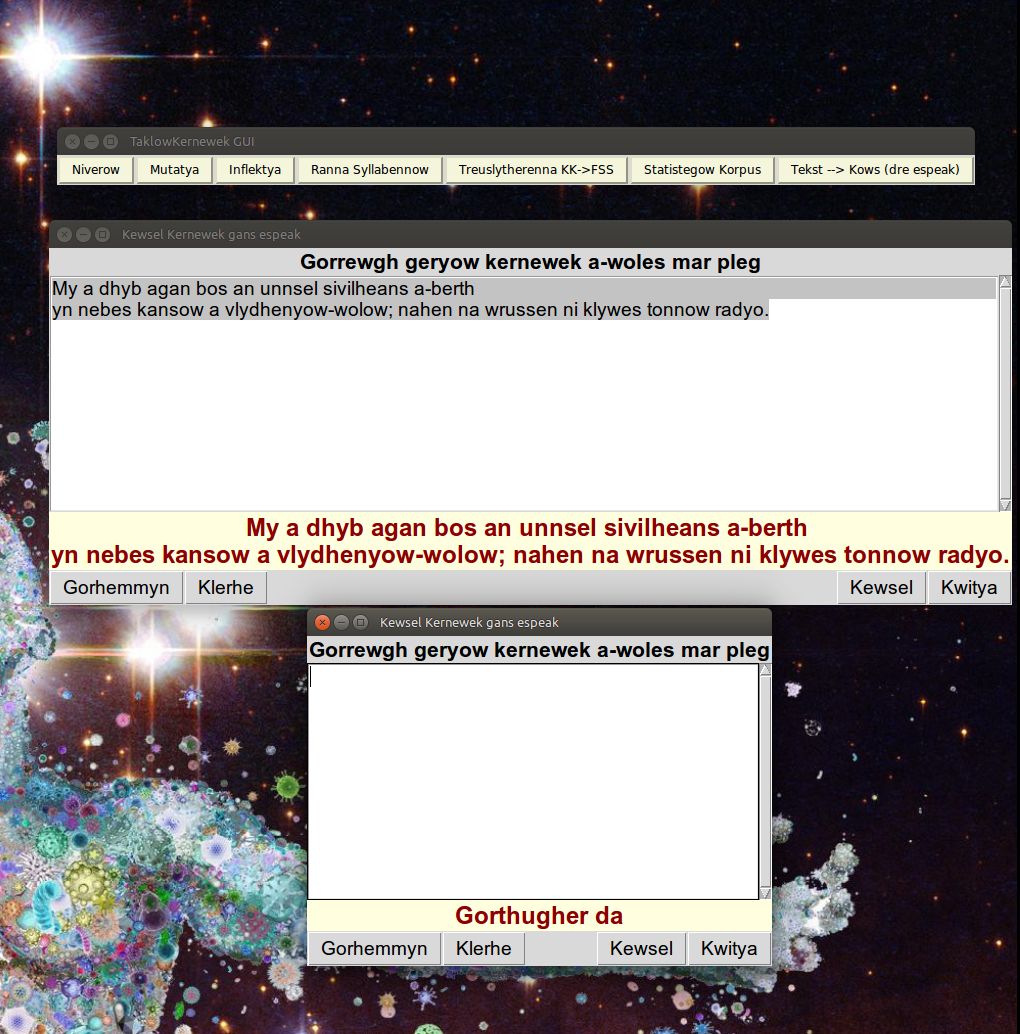 |
| The first quote as an mp3 file. The second is generated by pressing the "Gorhemmyn" button, and an appropriate greeting is chosen according to the system clock. |
Transliteration from Kernewek Kemmyn to Standard Written Form
The script treuslytherenna.py and its GUI frontend treuslytherennaGUI.py converts text from Kernewek Kemmyn to Standard Written Form (Main Form).
See also the brief writeup on my website, and earlier on this blog.
A couple of example sentences I use to illustrate some of its features are:
There was a tree in the forest is the translation of the first sentance, and gwydhennow is the plural of the singlative gwydhenn which derives from the collective noun gwydh (trees). Gwydh would be use for a general mass of trees, gwydhenn a single tree, and gwydhennow a countable collection of individual trees.

In the left hand panel, gwydhenn becomes gwedhen showing two changes, firstly the doubled consonant -nn becomes single -n. The program will make this change for unstressed syllables, exluding those that are prefixes that have secondary stress like penn- in pennseythun and some others.
The other change is the y becoming an e as part of vocalic alternation. This occurs for y vowels that are 'half-long' in Kernewek Kemmyn, which is detected via the syllable segmentation program.
The function converty(inputsyl) in treuslytherenna.py applies this change as long as the word isn't in a list of exceptions given in datageryow.py and the syllable ends in a consonant. If the syllable ends in a vowel (e.g. ay, ey, oy diphthongs, and -ya endings where the y (which is really a semi-vowel y) has been erroneously assigned to the previous syllable) the change is not made.
If backwards segmentation is chosen, this change won't happen since gwydhenn will be segmented into ['gwy', 'dhenn'] and the y will not be changed since it is now in a syllable ending in a vowel.
The word goeswik (mutation of koeswik) becomes goswik, as the Kernewek Kemmyn oe becomes o where it is a short or half-long vowel, and oo in a syllable with a Kernewek Kemmyn long vowel.
In the right hand panel, the word gwydhennow is unchanged, because the y vowel in the first syllable is now short rather than half-long, and the -nn is in a stressed syllable so retained as a double consonant.
See also the brief writeup on my website, and earlier on this blog.
A couple of example sentences I use to illustrate some of its features are:
- Yth esa gwydhenn y'n goeswik
- Yth esa gwydhennow y'n goeswik
There was a tree in the forest is the translation of the first sentance, and gwydhennow is the plural of the singlative gwydhenn which derives from the collective noun gwydh (trees). Gwydh would be use for a general mass of trees, gwydhenn a single tree, and gwydhennow a countable collection of individual trees.

In the left hand panel, gwydhenn becomes gwedhen showing two changes, firstly the doubled consonant -nn becomes single -n. The program will make this change for unstressed syllables, exluding those that are prefixes that have secondary stress like penn- in pennseythun and some others.
The other change is the y becoming an e as part of vocalic alternation. This occurs for y vowels that are 'half-long' in Kernewek Kemmyn, which is detected via the syllable segmentation program.
The function converty(inputsyl) in treuslytherenna.py applies this change as long as the word isn't in a list of exceptions given in datageryow.py and the syllable ends in a consonant. If the syllable ends in a vowel (e.g. ay, ey, oy diphthongs, and -ya endings where the y (which is really a semi-vowel y) has been erroneously assigned to the previous syllable) the change is not made.
If backwards segmentation is chosen, this change won't happen since gwydhenn will be segmented into ['gwy', 'dhenn'] and the y will not be changed since it is now in a syllable ending in a vowel.
The word goeswik (mutation of koeswik) becomes goswik, as the Kernewek Kemmyn oe becomes o where it is a short or half-long vowel, and oo in a syllable with a Kernewek Kemmyn long vowel.
In the right hand panel, the word gwydhennow is unchanged, because the y vowel in the first syllable is now short rather than half-long, and the -nn is in a stressed syllable so retained as a double consonant.
Syllable segmentation in Cornish - forward vs. backward segmentation
The syllable segmentation module of TaklowKernewek I have commented on earlier in this blog, and on my website.
However there is much more to discuss, and one aspect of this is that the program offers a choice between forwards and backwards segmentation.
This means either starting from the beginning of the word, and working forwards assigning the letters to particular syllables, or starting from the end and working backwards.
I present some of the code from the program, which is admittedly difficult to read, and if you like, skip down to the examples at the bottom. It may also be easier to read at my Bitbucket site.
The core of this program is a set of regular expressions, as follows:
In the actual segmentation of the word itself, the expressions
where
The
A similar effect can be seen in another sentence:
However there is much more to discuss, and one aspect of this is that the program offers a choice between forwards and backwards segmentation.
This means either starting from the beginning of the word, and working forwards assigning the letters to particular syllables, or starting from the end and working backwards.
I present some of the code from the program, which is admittedly difficult to read, and if you like, skip down to the examples at the bottom. It may also be easier to read at my Bitbucket site.
The core of this program is a set of regular expressions, as follows:
# syllabelRegExp should match syllable anywhere in a word
# a syllable could have structure CV, CVC, VC, V
# will now match traditional graphs c-, qw- yn syllable initial position
syllabelRegExp = r'''(?x)
((bl|br|Bl|Br|kl|Kl|kr|Kr|kn|Kn|kwr?|Kwr?|qwr?|Qwr?|ch|Ch|Dhr?\'?|dhr?\'?|dl|dr|Dr|fl|Fl|fr|Fr|vl|Vl|vr|Vr|vv|ll|gwr?|gwl?|gl|gr|gg?h|gn|Gwr?|Gwl?|Gl|Gr|Gn|hwr?|Hwr?|ph|Ph|pr|pl|Pr|Pl|shr?|Shr?|str?|Str?|skr?|Skr?|skw?|Skw?|sbr|Sbr|spr|Spr|sp?l?|Sp?l?|sm|Sm|tth|Tth|thr?|Thr?|tr|Tr|tl|Tl|wr|Wr|wl|Wl|[bckdfjvlghmnprstwyzBCKDFJVLGHMNPRSTVWZY]) # consonant
\'?(ay|a\'?w|eu|ey|ew|iw|oe|oy|ow|ou|uw|yw|[aeoiuy])\'? #vowel
(lgh|ls|lt|bl|br|bb|kl|kr|kn|kwr?|kk|n?ch|dhr?|dl|n?dr|dd|fl|fr|ff|vl|vv|gg?ht?|gw|gl|gn|ld|lf|lk|ll|mm|mp|nk|nd|nj|ns|nth?|nn|ph|pr|pl|pp|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rr|rj|rf|rs|sh|st|sk|ss|sp?l?|tt?h|tt|[bdfgljmnpkrstvw])? # optional const.
)| # or
(\'?(ay|a\'?w|eu|ew|ey|iw|oe|oy|ow|ou|uw|yw|Ay|Aw|Ey|Eu|Ew|Iw|Oe|Oy|Ow|Ou|Uw|Yw|[aeoiuyAEIOUY])\'? # vowel
(lgh|ls|lt|bl|bb|kl|kr|kn|kwr?|kk|cch|n?ch|dhr?|dl|n?dr|dd|fl|fr|ff|vl|vv|gg?ht?|gw|gl|gn|ld|lf|lk|ll|mm|mp|nk|nd|nj|ns|nth?|nn|ph|pr|pl|pp|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rr|rj|rf|rs|sh|st|sk|ss|sp?l?|tt?h|tt|[bdfgljmnpkrstvw]\'?)?) # consonant (optional)
'''
# diwethRegExp matches a syllable at the end of the word
diwetRegExp = r'''(?x)
((bl|br|Bl|Br|kl|Kl|kr|Kr|kn|Kn|kwr?|Kwr?|qwr?|Qwr?|ch|Ch|Dhr?\'?|dhr?\'?|dl|dr|Dl|Dr|fl|Fl|fr|Fr|vl|Vl|vr|Vr|vv|ll|gwr?|gwl?|gl|gr|gg?h|gn|Gwr?|Gwl?|Gl|Gr|Gn|hwr?|Hwr?|ph|Ph|pr|pl|Pr|Pl|shr?|Shr?|str?|Str?|skr?|Skr?|skw?|Skw?|sbr|Sbr|spr|Spr|sp?l?|Sp?l?|sm|Sm|tth|Tth|thr?|Thr?|tr|Tr|tl|Tl|wr|Wr|wl|Wl|[bckdfjlghpmnrstvwyzBCKDFJLGHPMNRSTVWYZ]\'?)? #consonant or c. cluster
\'?(ay|a\'?w|eu|ew|ey|iw|oe|oy|ow|ou|uw|yw|Ay|Aw|Ey|Eu|Ew|Iw|Oe|Oy|Ow|Ou|Uw|Yw|\'?[aeoiuyAEIOUY]\'?) # vowel
(lgh|ls|lt|bl|br|bb|kl|kr|kn|kwr?|kk|cch|n?ch|dhr?|dl|n?dr|dd|fl|fr|ff|vl|vv|gg?ht?|gw|gl|gn|ld|lf|lk|ll|mm|mp|nk|nd|nj|ns|nth?|nn|ph|pr|pl|pp|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rr|rj|rf|rs|sh|st|sk|ss|sp?l?|tt?h|tt|[bdfgjklmnprstvw]\'?)? # optionally a second consonant or cluster ie CVC?
(\-|\.|\,|;|:|!|\?|\(|\))*
)$
'''
# kynsaRegExp matches syllable at beginning of a word
# 1st syllable could be CV, CVC, VC, V
kynsaRegExp = r'''(?x)
^((\'?(bl|br|Bl|Br|kl|Kl|kr|Kr|kn|Kn|kwr?|Kwr?|qwr?|Qwr?|ch|Ch|Dhr?|dhr?|dl|dr|Dr|fl|Fl|fr|Fr|vl|Vl|vr|Vr|gwr?|gwl?|gl|gr|gn|Gwr?|Gwl?|Gl|Gr|Gn|hwr?|Hwr?|ph|Ph|pr|pl|Pr|Pl|shr?|Shr?|str?|Str?|skr?|Skr?|skw?|Skw?|sbr|Sbr|spr|Spr|sp?l?|Sp?l?|sm|Sm|tth|Tth|thr?|Thr?|tr|Tr|tl|Tl|wr|Wr|wl|Wl|[bckdfghjlmnprtvwyzBCKDFGHJLMNPRTVWYZ])\'?)? # optional C.
\'?(ay|a\'?w|eu|ew|ey|iw|oe|oy|ow|ou|uw|yw|Ay|Aw|Ey|Eu|Ew|Iw|Oe|Oy|Ow|Ou|Uw|Yw|[aeoiuyAEIOUY])\'? # Vowel
(lgh|ls|lk|ld|lf|lt|bb?|kk?|cch|n?ch|n?dr|dh|dd?|ff?|vv?|ght|gg?h?|ll?|mp|mm?|nk|nd|nj|ns|nth?|nn?|pp?|rgh?|rdh?|rth?|rk|rl|rv|rm|rn|rj|rf|rs|rr?|sh|st|sk|sp|ss?|tt?h|tt?|[jw]\'?)? # optional C.
(\-|\.|\,|;|:|!|\?|\(|\))*
)'''
In the actual segmentation of the word itself, the expressions
kynsaRegExp and diwetRegExp are used, depending on whether we are going forwards starting from the beginning or backwards from the end:
if fwds:
# go forwards
sls = rannans.ranna_syl(self.graph,regexps.kynsaRegExp,fwd=True,bwd=False)
else:
# go backwards from end
sls = rannans.ranna_syl(self.graph,regexps.diwetRegExp,fwd=False,bwd=True)
where
ranna_syl() is the actual function that returns a list of syllables from the word ger:
def ranna_syl(self,ger,regexp,fwd=True,bwd=False):
""" divide a word into a list of its syllables
and return this as a list of plain text strings
"""
syl_list = []
if fwd:
# go forwards through the word
while ger:
# print(ger)
k = self.match_syl(ger,regexp)
# print("kynsa syl:{k}".format(k=k))
# add the syllable to the list
if k != '':
syl_list.append(k)
if k != '' and len(ger.split(k,1))>1:
# if there is more of the word after the
# 1st syllable
# remove the 1st syllable
ger = ger.split(k,1)[1]
else:
ger = ''
if bwd:
# go backwards from the end through the word
while ger:
# print(ger)
d = self.match_syl(ger,regexp)
# print(d)
# add the syllable to the list
if d != '':
syl_list.insert(0,d)
if d != '' and len(ger.rsplit(d,1))>1:
# if there is more of the word before the
# last syllable
# remove the last syllable
ger = ger.rsplit(d,1)[0]
else:
ger = ''
# this is returning
# a list of plain text
# not Syllabenn objects
return syl_list
The
syllabelRegExp regular expression is used in Syllabenn class itself, as part of the code that initates a Syllabenn object and works out the syllable parts, i.e. consanant clusters and vowels, and the overall length.Example sentences
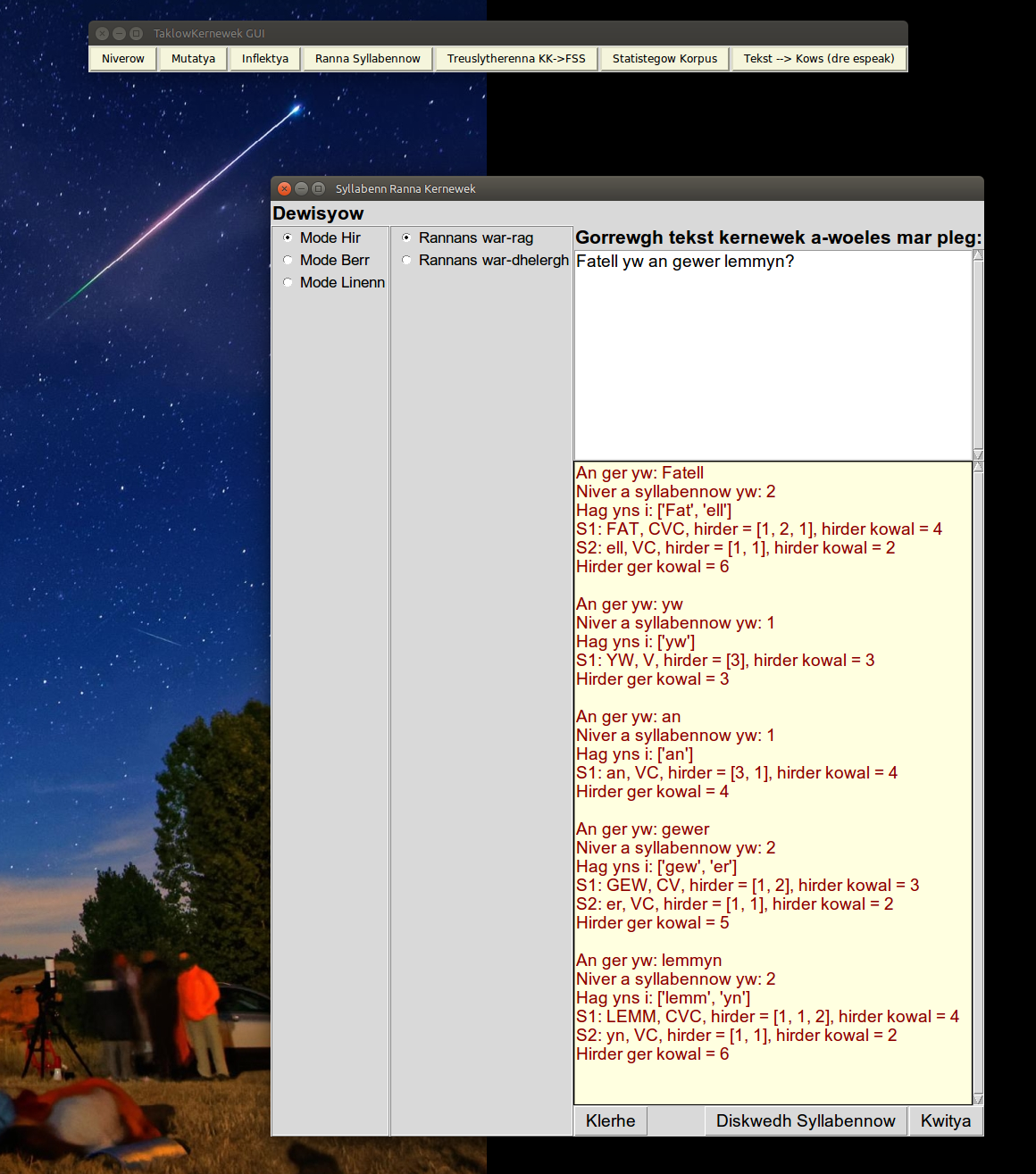
The effect of going forwards or backwards can be illustrated in the processing of an example sentence: |
| Going backwards from the end, tends to maximise consonants at the beginning of syllables. For example the word 'gewer' is processed into ['ge', 'wer'] i.e. the w is assigned to the second syllable whereas in this word the 'ew' is actually pronounced as a diphthong. The gemminated consonant 'mm' in lemmyn is split into two different syllables. |
 | |
| Now working forward, the processing of the word 'gewer' now splits into ['gew', 'er'] which accords with the status of 'ew' as a diphthong. 'Lemmyn' now splits into ['lemm', 'yn'] assigning the whole of the gemminated consonant to the first syllable. The word 'Fatell' now has the 't' assigned to the first syllable |
A similar effect can be seen in another sentence:
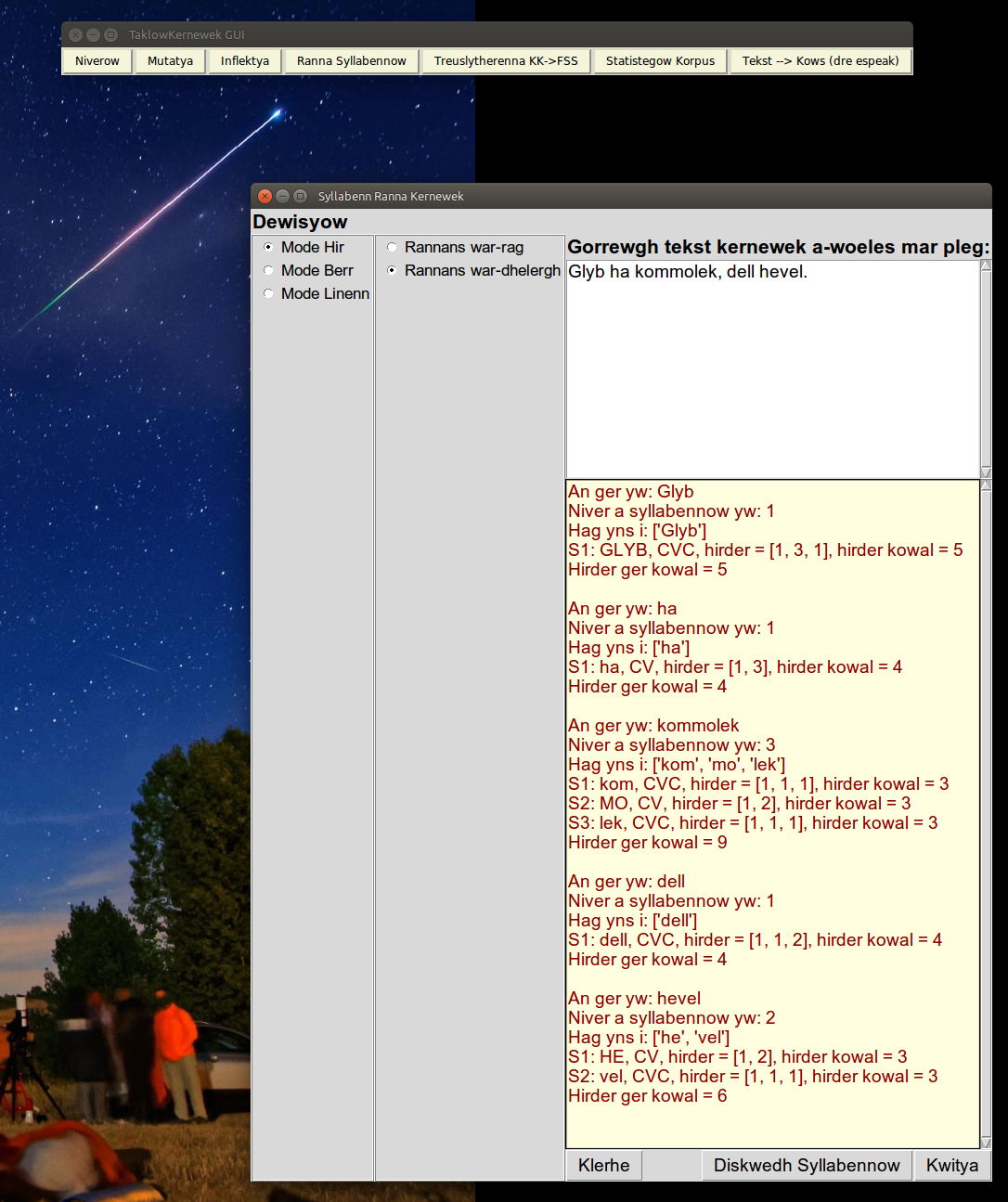 |
| Special cases such as the unstressed monosyllables 'ha', and 'dell' are detailed in the file datageryow.py. |
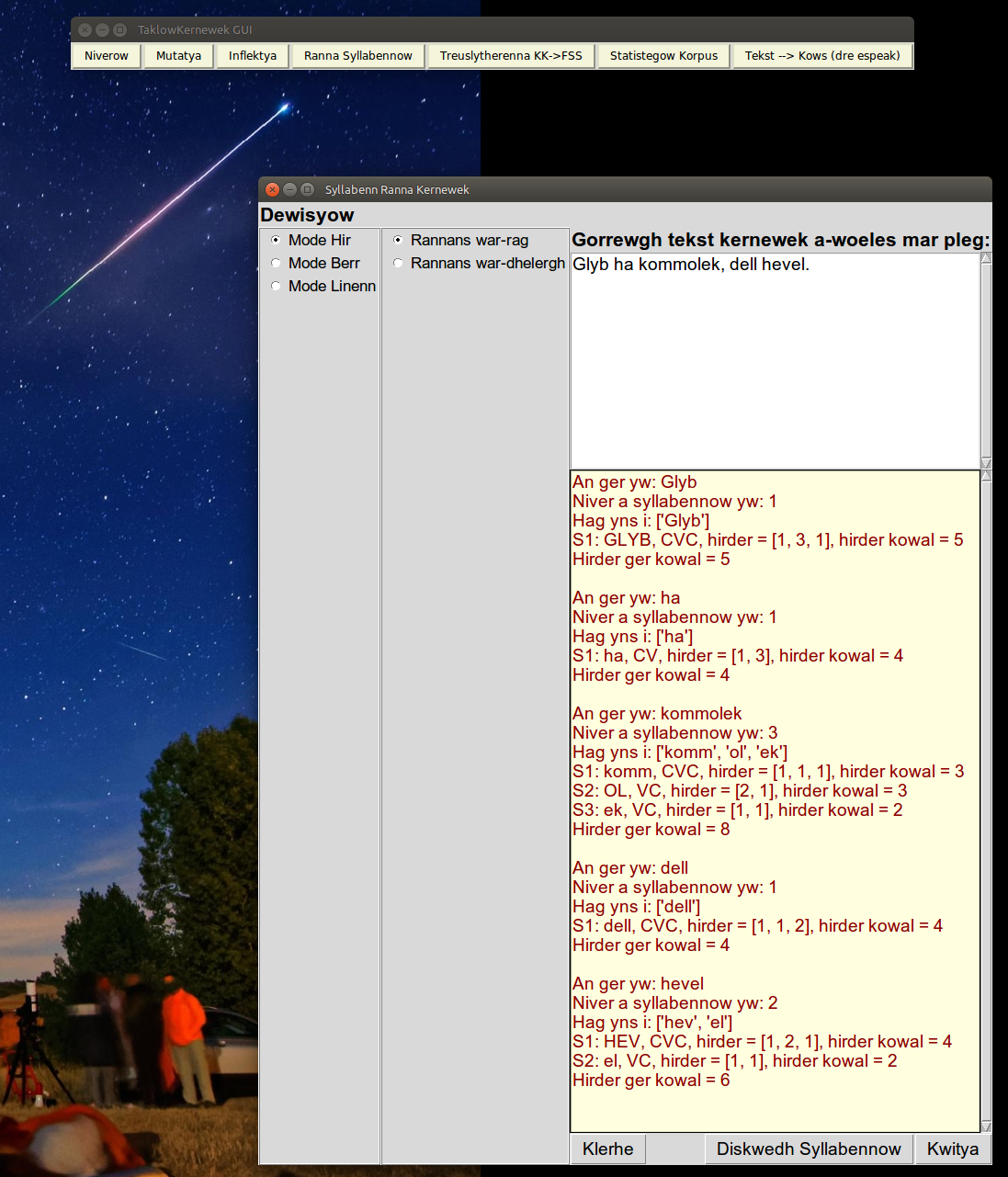 |
| With forwards segmentation, the processing of 'kommolek', and 'hevel' assigns consonants to the coda of syllables rather than maximising the onset. |
An update on TaklowKernewek - Cornish language Python tools
I have been continuing a little more development on my Cornish language processing tools.
I have added recently a number of things to them, including reverse mutation, and a launcher program. In this post, I will describe a little of 'Niverow', a program to write out numbers in Cornish, 'Mutatya' - a program to generate mutated forms of words, and 'Inflektya', a program to generate inflected verb forms.
Firstly the launcher program. This is the file TaklowKernewekLonchyer.pyw
which itself imports a couple of other scripts TaklowKernewekLonch.py and launchmodes.py which are largely based on example scripts from Programming Python 3rd edition by Mark Lutz.
Running this brings up a basic array of buttons:
The other new feature is reverse mutation, taking a word and identifying what words it could originally have been. This doesn't check whether the hypothesised unmutated word actually exists, or whether the mutation is actually gramatically possible.
I have added recently a number of things to them, including reverse mutation, and a launcher program. In this post, I will describe a little of 'Niverow', a program to write out numbers in Cornish, 'Mutatya' - a program to generate mutated forms of words, and 'Inflektya', a program to generate inflected verb forms.
Firstly the launcher program. This is the file TaklowKernewekLonchyer.pyw
which itself imports a couple of other scripts TaklowKernewekLonch.py and launchmodes.py which are largely based on example scripts from Programming Python 3rd edition by Mark Lutz.
Running this brings up a basic array of buttons:
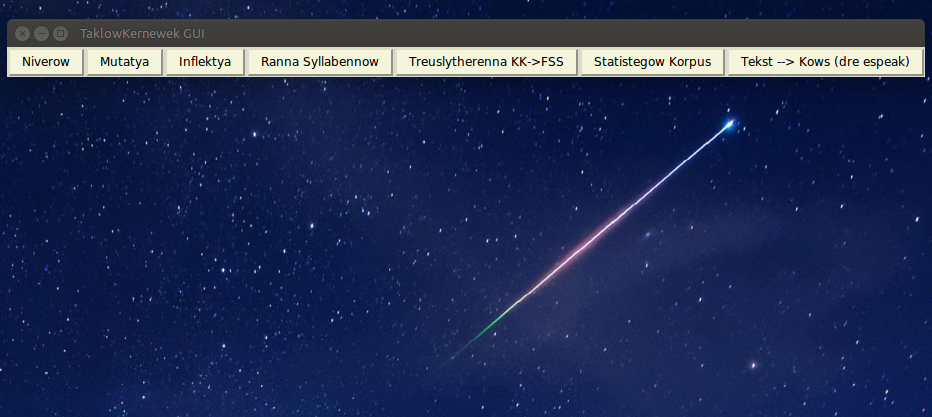 |
| Clicking on any of these buttons will bring up its own GUI window. |
Niverow
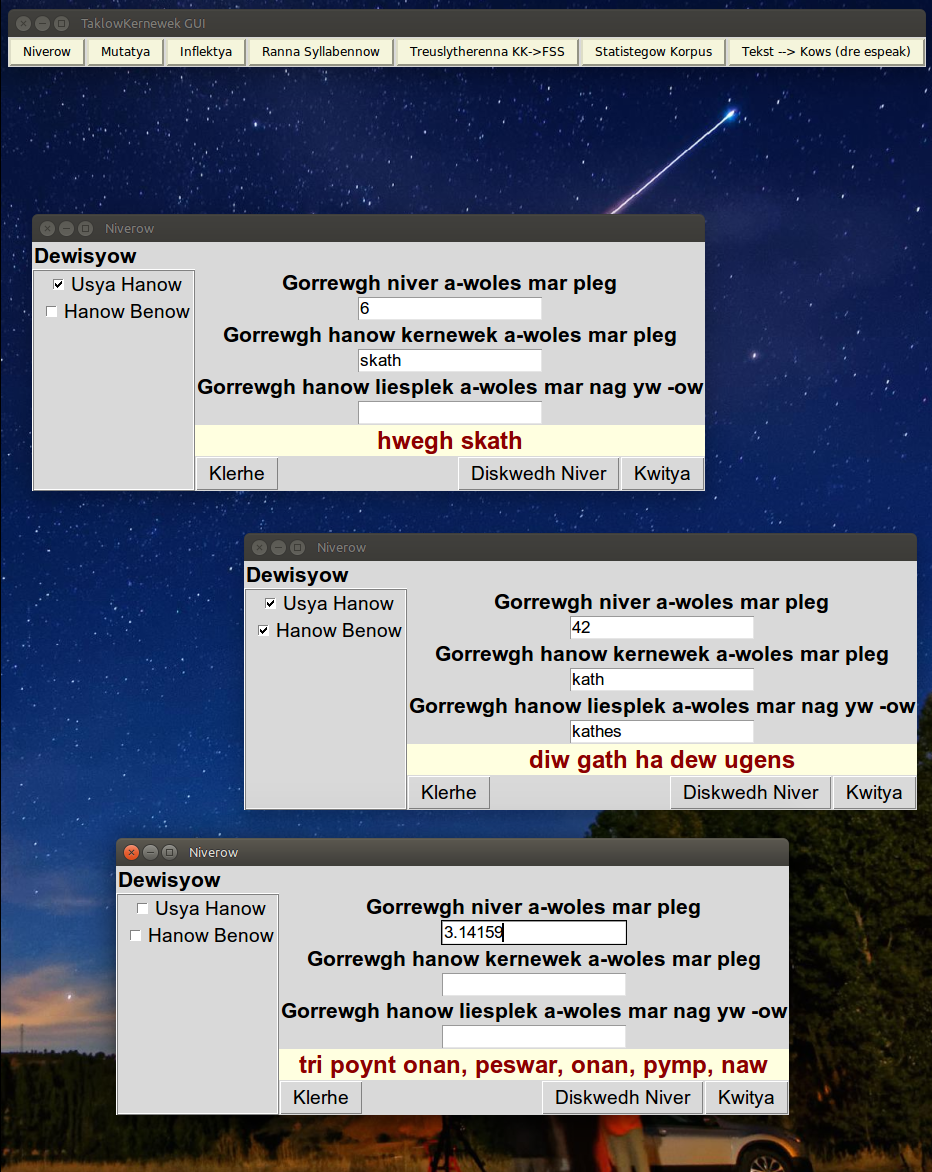 |
| In the boxes, specify the number, and the noun, and noun plural, if you wish to include the noun. It is also necessary to tick the box next to "Usya Hanow" to do so. Tick "Hanow Benow" to indicate that it is a feminine noun, which will make the program use the feminine forms of numbers (e.g. diw in place of dew) where they are needed. Decimal numbers can be used, and this program treats them reading out one digit at a time. |
 |
| If using a decimal number, the program will use the number + a + plural noun format. The plural is assumed to be the noun + -ow unless a different one is specified. |
 |
| This format is also used if the number has more than three elements |
Mutatya
I have mentioned mutatya.py before on this blog, but it has a few new features including an option to use the traditional spelling forms as used in the SWF Traditional variant. These consist of using c instead of k before some vowels, and using qw- instead of kw- and wh- instead of hw-.The other new feature is reverse mutation, taking a word and identifying what words it could originally have been. This doesn't check whether the hypothesised unmutated word actually exists, or whether the mutation is actually gramatically possible.
 |
| Traditional forms of the soft mutation c-->g, and the hard mutation gw-->qw. These would be k-->g and gw-->kw in Kernewek Kemmyn, or SWF Main Form. |
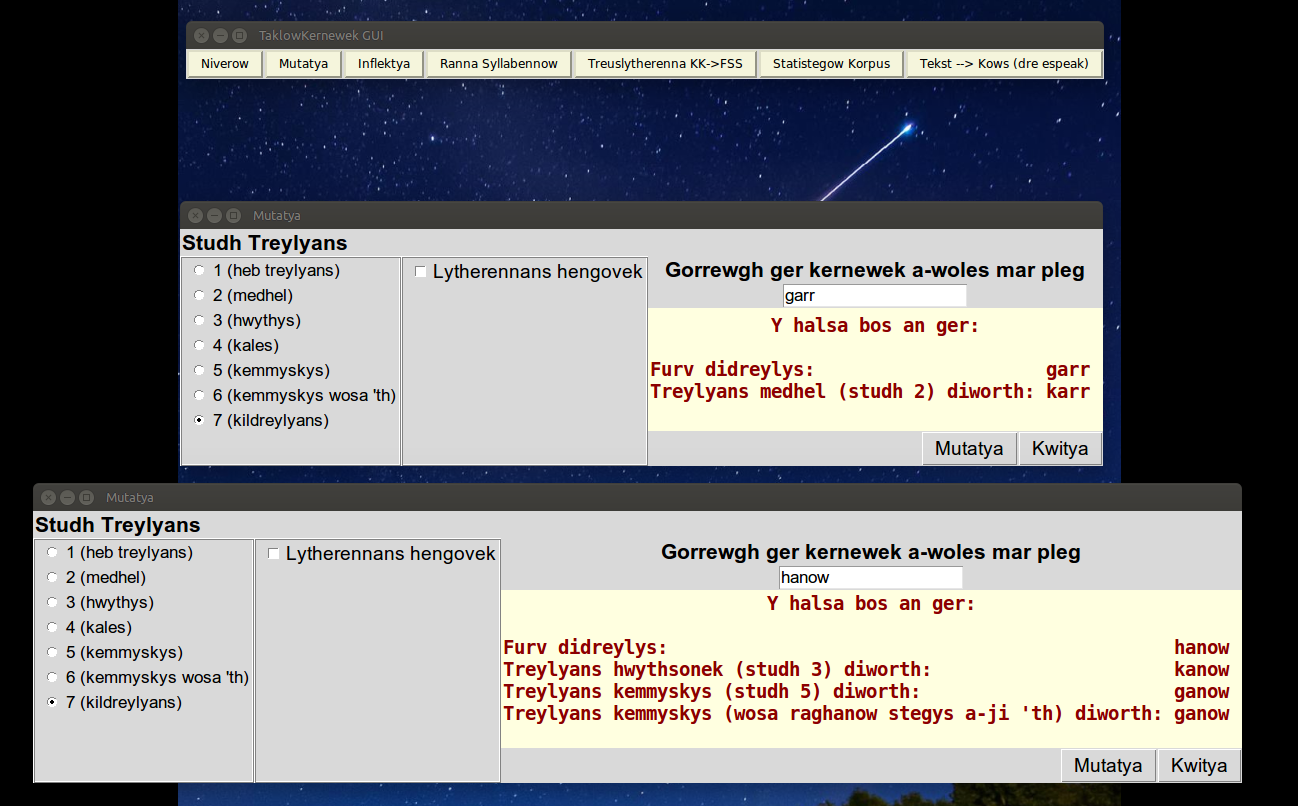 |
| The word 'garr' could either be an unmutated form, or a soft mutation of 'karr'. Likewise 'hanow' could be 'hanow', breathed mutation of 'kanow' or mixed mutation of 'ganow'. |
Inflektya
This program generates inflected forms of verbs, selecting the tense in the left hand menu, the person in the next one, whether to use suffixed pronouns, and whether to expect SWF input and give SWF output (the default is Kernewek Kemmyn).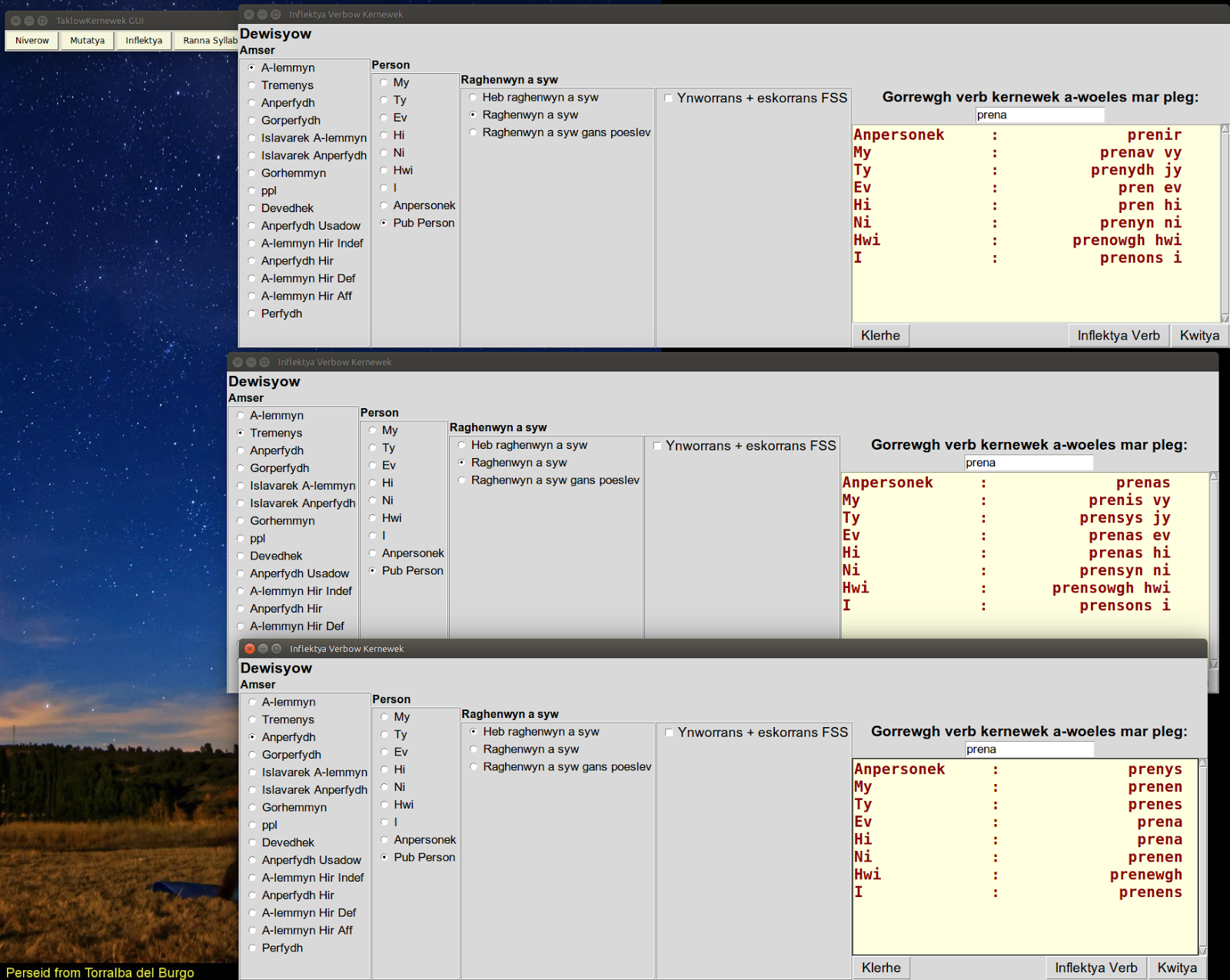 |
| Showing the inflected forms of the regular verb 'prena' for present, preterite, and imperfect tenses. |
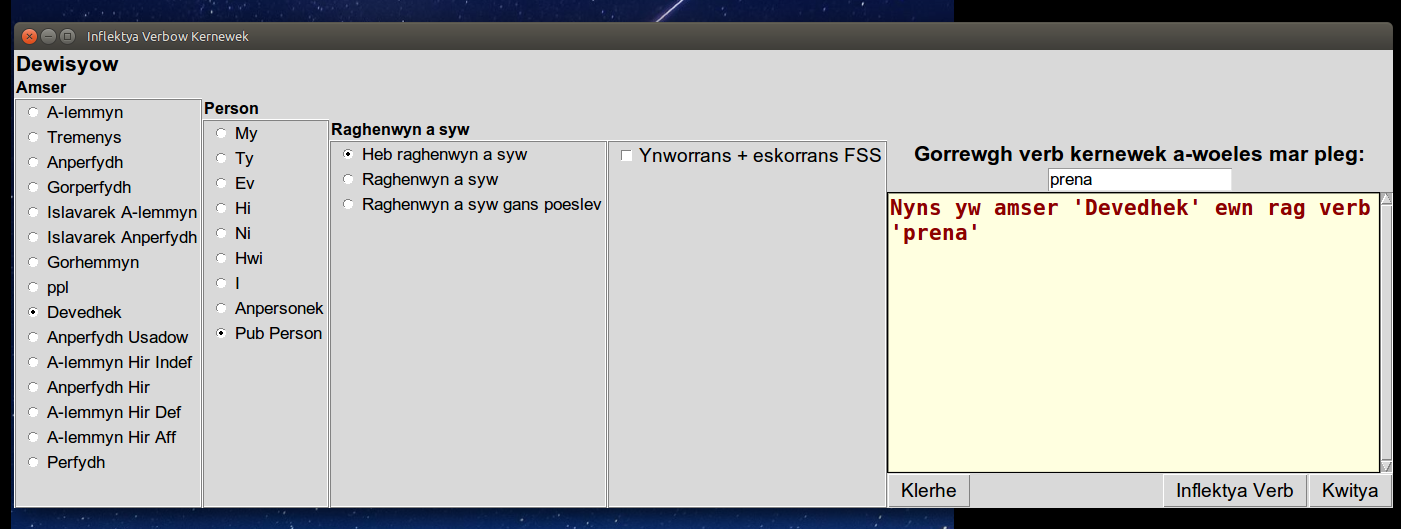 |
| Attempting to show the future tense of prena gives an error message, since the simple future doesn't exist for this verb. |
 |
| The imperative, which doesn't exist for the impersonal, and first person forms, and is not very common except in 2nd person 'Ty' and 'Hwi' forms. |
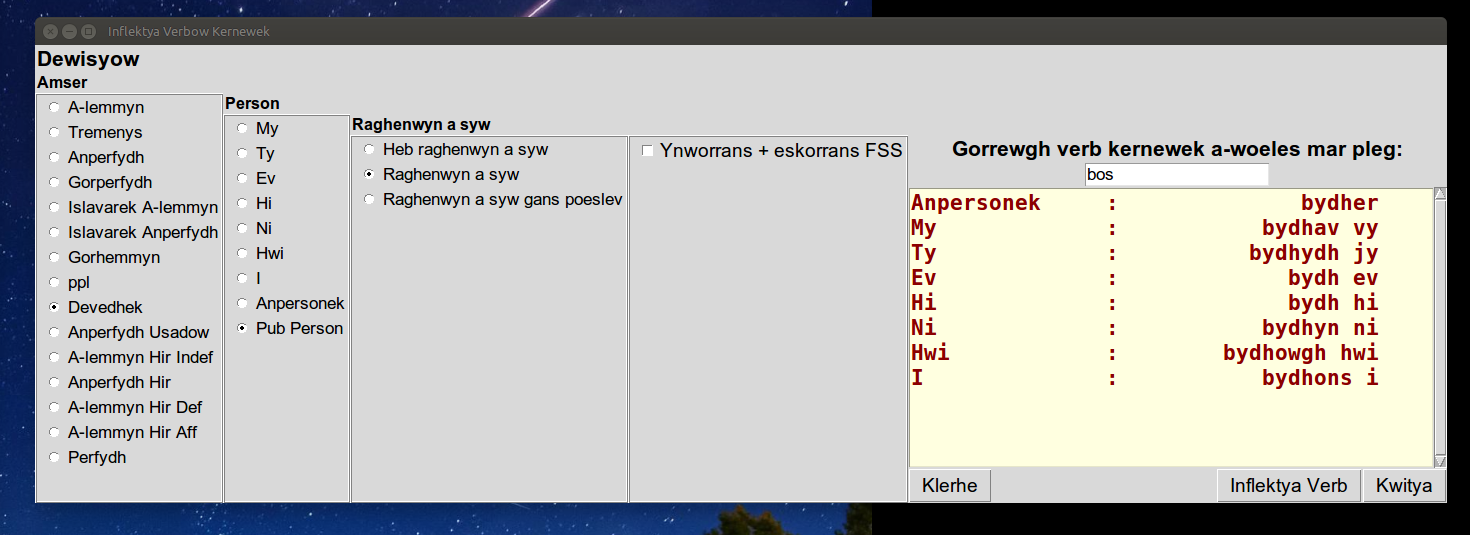 |
| For the irregular verb 'bos' to be, the simple future is shown. |
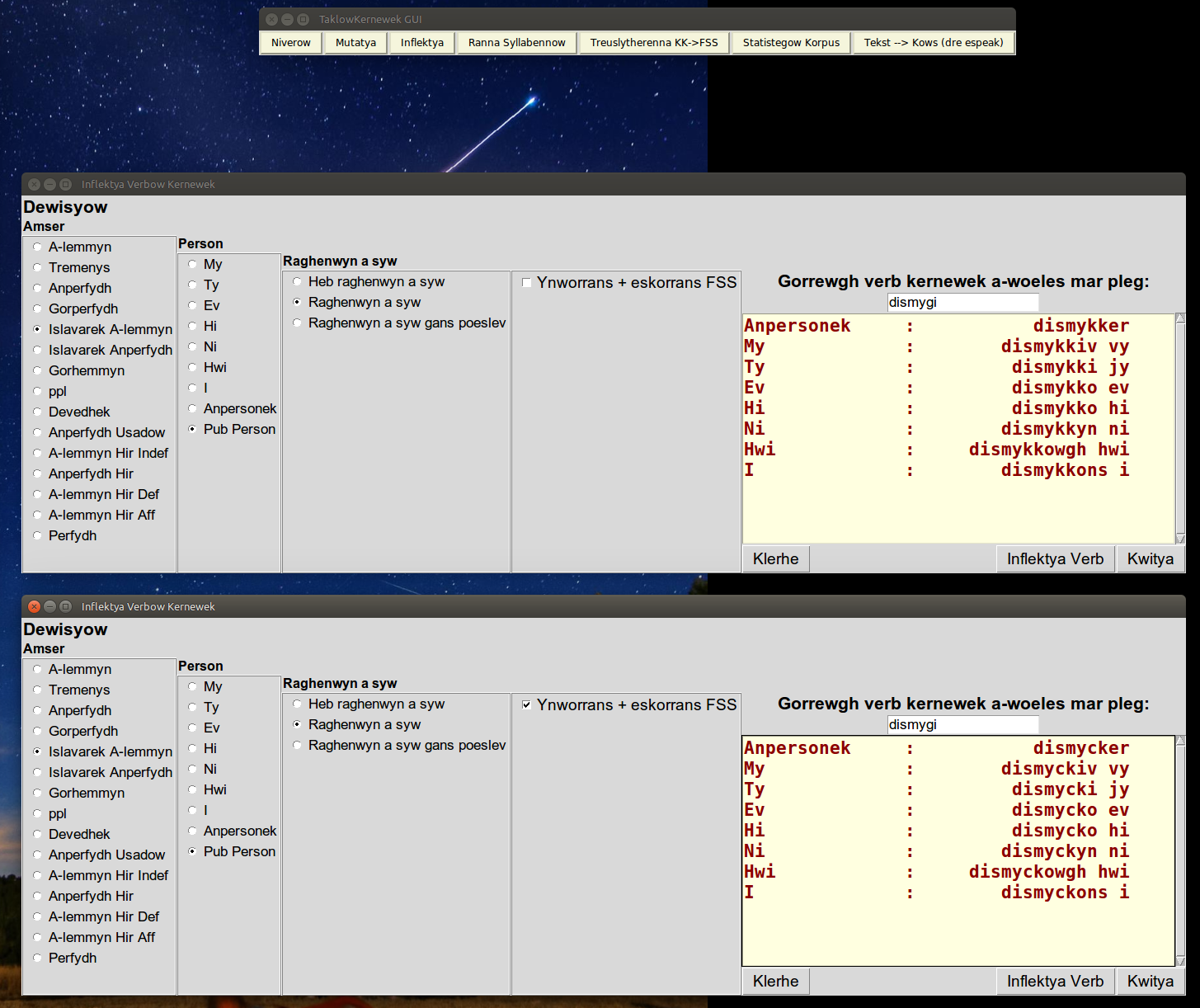 |
| The present subjunctive of the verb 'dismygi' in Kernewek Kemmyn, and in SWF. |
Welsh language internet memes
Here's a few captioned pictures in Welsh I put out on clecs.cymru (like Twitter, but in Welsh) previously and a couple of Cornish ones:
 |
| Based on the song Can y Cardi |
 |
| Mae Powys yn wlad fawr iawn. Scattered towns separated by vast tracts of conifers... |
 |
| Mae e yn Forg! |
 |
| A typical summer Saturday on the main train line through Cornwall. In Cornish it is not recommended to use "war an tren", instead "y'n tren" if you are indeed travelling inside the carriage. |
 |
| This may look similar to a screenshot from Poldark but it is in fact from the Cornish version of Lord of the Rings, in a scene showing the hobbits in the Old Forest (An Hen Goeswik or An Goeswik Goth). |
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
Next »